The endless possibilities of RAG based LLM applications

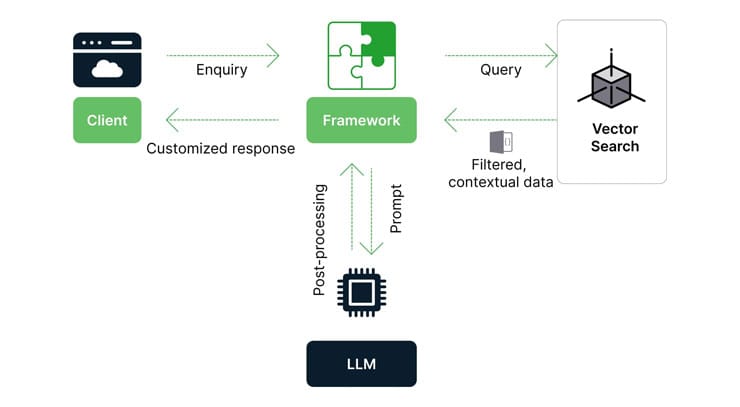
Our vision is to build industry-trained LLMs that actually allows people to discover and explore insights. So, we start by processing external data sources through Retrieval Augmented Generation(RAG) to augment LLM capabilities. Specifically, we are building a Mei Agent that can answer questions about any website it “reads”. If you have a website for your business and you want to create a powerful yet easy-to-use tool that can answer any question your website visitors ask, Mei can help you do that. So basically, Mei Chat helps your website talk back to your visitors and give them answers. This changes the very fundamentals of how a user interacts with a digital platform and receives information. We will explain how an RAG-based LLM application works in this article.
RAG Makes LLMs very useful. How?
A generic AI or foundational model only offers general Information- barely scratching the surface of what people and brands can do with AI. It's not focused on a business or domain. It primarily misses private data that is specific for your business and industry. Thus, the responses are not personalized for any of your particular problems or use cases. However, If LLMs are clubbed with vector search and RAG, it becomes a game-changer for enterprises, to say the least. The vector search brings in company-specific data and the context surrounding it, carefully crafting responses that are more and more rooted in the nuances of your business. Unlike other AI applications that treat this technology as just adding another slab over your current digital strategy, Mei actually brings this technology to your enterprise’s digital DNA- powering every move, no matter how small or big, with AI.
Vector Database:
Vector Database is a really crucial part of a RAG application. In order to store the processed data, we need a Vector Database. As vector databases play a crucial role in semantic search and performance, we have to pick the top vector database that's available in the market. We will talk about Vector Database in subsequent blogs but right now, let's continue with any open source Vector Database.
From various data sources such as web pages, PDFs, and images, data must be extracted and loaded. Data extraction should not be taken easily as this is vital for any AI Solution. It could be PDF Parser, HTML Parser or Image readers, data should be extracted from various sources and chunking, embedding and indexing must be done properly. The Industry is moving towards converting all content to PDF and extracting data from PDF. Building such a great Parser engine is vital for perfect data extraction.
Once the extraction is done, it must be loaded as sections in the vector database. For significant usage and retrieval of valuable information from semantic search, data must be chunked based on context. Chunking can be done either by a fixed-size chunking method or content-aware chunking. If chunking is not done properly, the data gets stored and retrieval will not be accurate.
Now chunks are created and we have to identify the relevant chunks for a given query. An effective way is to embed our data using any pre-trained model. We will have to identify the perfect pre-trained model to train and embed our data. Once the embedding is done, it's time to index this in VectorDB for quick retrieval.
If a query is asked to a chat agent, any current Large language models such as OpenAI, Llama, or Gemini will give a response for the query. However, in order to get the response based on the context, we will have to pass the query to the vector database and capture the contextual response for the query and only then it must be passed to LLM to generate the content surrounding the context. Also, the chat agent should be intelligent enough to do a variety of sub-tasks that understand the purpose, and emotions of the query and can also invoke different LLMs or algorithms based on the query. This should also have the provision to integrate with enterprise data to fetch appropriate and truthful insights about their business; which is our long-term goal and we’re getting a step closer everyday.
Scalable RAG Application :
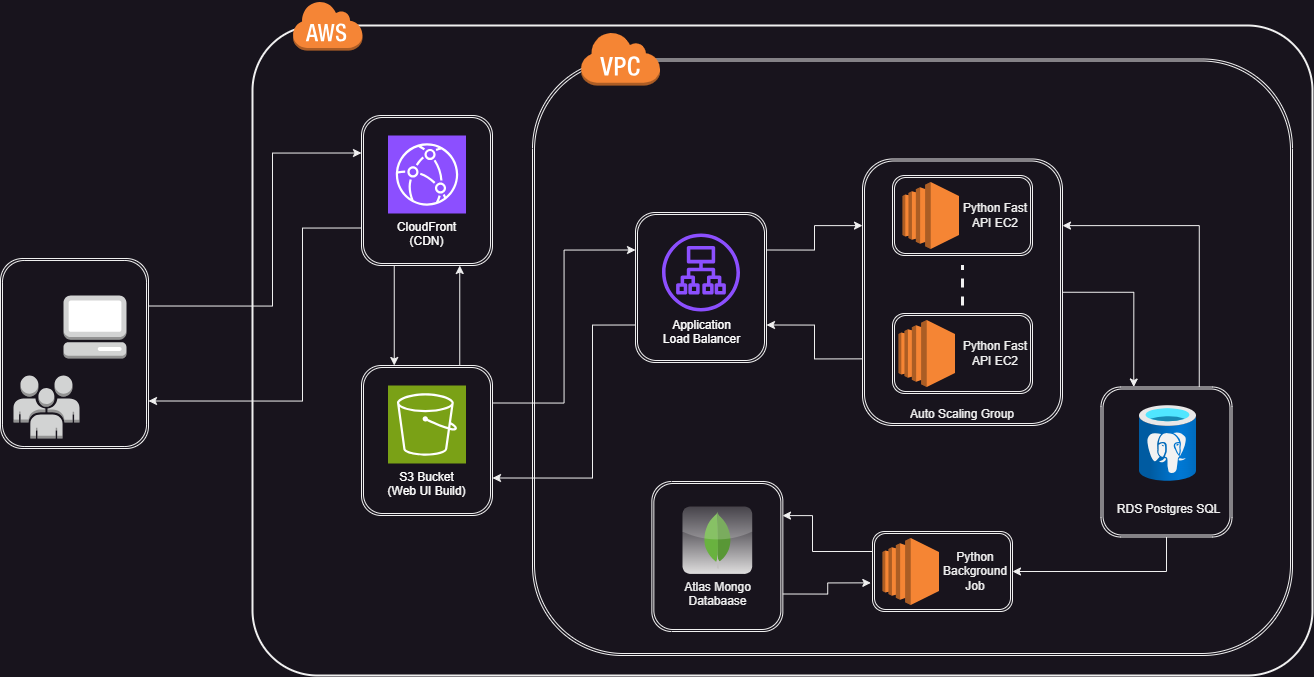
During different sessions and discussions between our ML engineers and enterprises, the primary concern is to build a Scalable RAG Application. This restricts them from building their own RAG app and rather stick with private LLMs which brings the risk of connecting their secured data sources to the private LLMs. Here is one of the solutions that can be built with Amazon Web Services which is completely scalable, privately deployed, and secure for enterprises.
Post Response validation :
Now the Application gives responses to a variety of queries and it is time to evaluate and optimize the response. In order to get better results, we will have to do prompt engineering, relevance, and Truthfulness and also bring in Ethical QA.
Prompt Engineering:
It refers to the systematic design and optimization of Input prompts that actually guide the responses of LLMs. This is crucial to get better outputs from the models. The input prompt could follow the ‘Giving Instructions” or “Clear/precise” method. Role prompting, one-shot prompts, or standard prompts are also additional methods for better prompt engineering.
Truthfulness and Relevance:
Now the Agent and Foundation model / LLM combination gives responses, we will have to verify whether the response is relevant to the question and also the authenticity/truthfulness of the response. Right now the market is working towards comparing the response from a variety of LLMs to find the truthfulness, but practically it will not be the best solution and should find a better-automated way to evaluate.
And scene…
Sometimes, the product is an idea. And we strongly believe that Mei falls into this category. We are cutting against the grain, challenging the status quo to make the most out of Artificial Intelligence. We bet on this technology because we have witnessed firsthand the impact it can deliver for people, brands, and governments. Our entire team is betting on the collective knowledge and spirit of humanity as we turn the next page of our future. We aim to simplify this powerful technology so that it can guide millions of people and businesses. Follow us if you want to witness and be a part of our journey.
Frequently Asked Questions
What is a RAG based application?
RAG stands for Retrieval-Augmented Generation. This is an architecture which connects out internal data with LLM and can be used for a variety of purposes like conversation AI, sentiment analysis etc.
Why choose RAG architecture for building LLM applications?
In order to make LLM work with our internal data. RAG architecture provides a method to connect our documents, text files and even database to the LLM. It also helps for performing a semantic search on our internal database.
How does RAG contribute to the scalability of LLM applications?
As new data gets into the system, in the RAG architecture we have to perform the indexing. In most of the cases indexing is much faster and the application is available and ready to use immediately after the indexing is complete. In case of fine tuning, we need to train the model with the additional data that has come into the system and it is time consuming process.
Is RAG suitable for both small-scale and large-scale LLM applications?
Yes, Retrieval-Augmented Generation can be used for all purpose, both small-scale and large-scale
What are the benefits of rag in the context of LLM?
We can get started even if there are multiple sources of data.
It does not take much to structure the data.
Once the RAG architecture is setup we can use it for various purposes like Question answering, semantic search etc. The cost of setting up RAG is much less compared to fine tuning for internal data.
Can MEII AI build my RAG Application?
Yes absolutely. We can work with you right from the beginning to collect all the data sources. If there is a need for data cleaning, we would provide suggestions for the same. Once the data is collected, we have an ingestion pipeline to get the entire data indexed. The rest of the elements of the architecture are connected seamlessly with the data.We have an advanced architecture which processes the data with utmost parallelism. The application would be ready for use. We also provide API for your data and you can integrate with other tools.
We have our home grown retrievers for getting quality results from the internal data. We also have a process of checking if the LLM is providing relevant and truthful answers.